How Docker's new business model unblocked image visualization
With the early access release of Docker Scout, Docker Hub is finally beginning to visualize image internals. This is great! Why didn't Docker Hub do this years ago? Because of its business model.
Before we go further, let's briefly review what Docker images are made of.
Docker images are made of layers
When you download a Docker image by running docker pull at the command line, the Docker CLI displays each
layer's download progress as it pulls the image. If you've ever downloaded a Docker image, you've probably seen it:

If you've worked with Docker before, you've likely defined some of these layers for your own images. Developers implicitly define these layers when they write Dockerfiles. For example, every line in this Dockerfile produces a layer:
1FROM ubuntu:22.04
2
3# install apt dependencies
4RUN apt-get update
5RUN apt-get install -y iputils-ping python3 python3-pip
6
7# install python dependencies
8RUN pip3 install numpy
9
10# cleanup apt lists
11RUN rm -rf /var/lib/apt/lists/*
12
13CMD ["/bin/bash"]Layers are archived Linux directories—they're file system tarballs. Docker downloads all of your image layers
and unpacks each of them into a separate directory. When you launch a container from a Docker image using the
docker run command, the Docker daemon combines the image layers together to form a container.
A lot of Docker's value-add as a product is that it abstracts away these details, letting users reap the benefits of layered containers without thinking about how they work. But all abstractions leak, and Docker is no exception—sometimes, you need to pull back the curtain.
Why developers look at Docker image internals
Supply chain inspection
Docker image layers contain the origin story for every binary present in the container's file system. The first line in a Docker image is "the FROM line". It defines the Docker image (and thus, the image layers) that the Dockerfile builds on top of.

By inspecting the layers from the current Dockerfile and the layers from its parent image chain, developers can determine where every file in a container's root file system came from. This is very valuable information. It helps developers:
- Abide by software licensing agreements
- Pass compliance audits more smoothly
- Detect and avoid security vulnerabilities
Imagine clicking through the layers in a visualization to trace file changes across Docker image versions. When an automated security scan identifies a vulnerability in one of your images, imagine using a layer inspection tool to identify how the vulnerability was introduced.
Image size optimization
Excessive image sizes can cost companies a lot of money. Many CI/CD pipelines pull Docker images for every pull request, so lengthy Docker image downloads can slow down pipelines, making developers less efficient and wasting CPU time. Because organizations typically pay infrastructure costs on an hourly basis, every hour wasted is an unnecessary expense.
Beyond wasted compute resources, bloated Docker images can lead to excessive network transfer costs. If an organization downloads Docker images across AWS regions, or out from AWS to the open internet, Docker image bloat directly translates to wasteful infrastructure spend. This adds up quickly.

It's easy to accidentally introduce bloat into your Docker image layers. The Dockerfile depicted earlier contains a classic example—the layer from line 4 saves 40MB of files on disk, which get deleted later on by the layer from line 11. Because of how Docker images work, that data is still part of the image, adding 40MB of unnecessary image size.
This is a simple example—in fact, it is straight out of Docker's documentation. In more complex Dockerfiles, this mistake can be much more difficult to spot.
How developers used to look at Docker image internals
Docker image layers can be difficult to interact with using the command line, but before Docker Scout was released recently, the command line was where you'd find the state of the art. Here are the two basic approaches.
Start a container and look at it
This is the no no-frills, do-it-yourself Unix method. All you need is a host running a Docker daemon. It's a simple approach:
- Run
docker createto start a container from the image. - Use
docker inspectto find the new container's layer directories. - Correlate those layer directories with the lines in the Docker image.
cdinto those directories at the command line and reason about the layers in your head.
This is a hassle. Let's say we're trying to track down some image bloat in a Docker image that we've been using for a few months but which has recently grown significantly in size. First, we create a container from the image:
where-the@roadmap-ends ~ $ docker create --name example where-the-roadmap-ends
339b8905b681a1d4f7c56f564f6b1f5e63bb6602b62ba5a15d368ed785f44f55Then, docker inspect tells us where the downloaded image's layer directories ended up on our file system:
where-the@roadmap-ends ~ $ docker inspect example | grep GraphDriver -A7
"GraphDriver": {
"Data": {
"LowerDir": "/var/lib/docker/overlay2/1c18bd289d9c3f9f0850e301bf86955395c312de3a64a70e0d0e6a5bed337d47-init/diff:/var/lib/docker/overlay2/wbugwbg23oefsf678r7anbn4f/diff:/var/lib/docker/overlay2/j0dekt7y8xgix11n0lturmf8t/diff:/var/lib/docker/overlay2/zd57mz6l4zrsjk9snc2crphfq/diff:/var/lib/docker/overlay2/83za1pmv9xri44tddzyju0usm/diff:/var/lib/docker/overlay2/8c639b22627e0ad91944a70822b442e5bff848968263a37715a293a15483c170/diff",
"MergedDir": "/var/lib/docker/overlay2/1c18bd289d9c3f9f0850e301bf86955395c312de3a64a70e0d0e6a5bed337d47/merged",
"UpperDir": "/var/lib/docker/overlay2/1c18bd289d9c3f9f0850e301bf86955395c312de3a64a70e0d0e6a5bed337d47/diff",
"WorkDir": "/var/lib/docker/overlay2/1c18bd289d9c3f9f0850e301bf86955395c312de3a64a70e0d0e6a5bed337d47/work"
},
"Name": "overlay2"The layers that we want to look at for this investigation are the list of "LowerDir" directories. The other directories are not part of the Docker image itself—we can ignore them.
So, we parse out the list of "LowerDir" directories at the command line:
where-the@roadmap-ends ~ $ docker inspect example | grep GraphDriver -A7 | grep LowerDir | awk '{print $2}' | sed 's|"||g' | sed 's|,||g' | sed 's|:|\n|g'
/var/lib/docker/overlay2/1c18bd289d9c3f9f0850e301bf86955395c312de3a64a70e0d0e6a5bed337d47-init/diff
/var/lib/docker/overlay2/wbugwbg23oefsf678r7anbn4f/diff
/var/lib/docker/overlay2/j0dekt7y8xgix11n0lturmf8t/diff
/var/lib/docker/overlay2/zd57mz6l4zrsjk9snc2crphfq/diff
/var/lib/docker/overlay2/83za1pmv9xri44tddzyju0usm/diff
/var/lib/docker/overlay2/8c639b22627e0ad91944a70822b442e5bff848968263a37715a293a15483c170/diffThese are the list of layers in the image, in order, with the lowest layer first. Now we need to manually correlate
these layer directories with the Dockerfile lines that produced them. Unfortunately, Docker does not give us a way
to directly extract these lines from a Docker image—this is the best we can get using docker history:
where-the@roadmap-ends ~ $ docker history where-the-roadmap-ends
IMAGE CREATED CREATED BY SIZE COMMENT
6bbac081b2a7 2 hours ago CMD ["/bin/bash"] 0B buildkit.dockerfile.v0
<missing> 2 hours ago RUN /bin/sh -c rm -rf /var/lib/apt/lists/* #… 0B buildkit.dockerfile.v0
<missing> 2 hours ago RUN /bin/sh -c pip3 install numpy # buildkit 70MB buildkit.dockerfile.v0
<missing> 2 hours ago RUN /bin/sh -c apt-get install -y iputils-pi… 343MB buildkit.dockerfile.v0
<missing> 2 hours ago RUN /bin/sh -c apt-get update # buildkit 40.1MB buildkit.dockerfile.v0
<missing> 8 months ago /bin/sh -c #(nop) CMD ["bash"] 0B
<missing> 8 months ago /bin/sh -c #(nop) ADD file:550e7da19f5f7cef5… 69.2MB Using this output, we can identify which layers have directories and which Dockerfile command created the layer (shown in the CREATED BY column).
The docker history command outputs the layers in your container in the same order as docker inspect
lists the layer directories. Knowing this, we can manually merge the two outputs together to see which layers are
larger than others, which Dockerfile command created them, and which directory contains each layer.
Here's the contents of Layer A, which performs an apt-get update:
where-the@roadmap-ends ~ $ du -hs /var/lib/docker/overlay2/83za1pmv9xri44tddzyju0usm/diff/var/lib/apt/lists
38.2M /var/lib/docker/overlay2/83za1pmv9xri44tddzyju0usm/diff/var/lib/apt/listsCompared to the contents of layer B, that deletes the files left over from Layer A:
where-the@roadmap-ends ~ $ du -hs /var/lib/docker/overlay2/wbugwbg23oefsf678r7anbn4f/diff/var/lib/apt/lists
4.0K /var/lib/docker/overlay2/wbugwbg23oefsf678r7anbn4f/diff/var/lib/apt/listsThe /var/lib/apt/lists directory exists in both layers, but in Layer B, the directory uses almost no space.
That's because layer B's directory contains "whiteout files", which Docker uses to mark files for exclusion from the final container file system.
Because of this, despite the files being "deleted" in Layer B, they still exist in Layer A, and thus contribute to the overall size of your image—38.2 MB of unnecessary bloat.
Now, wasn't that easy? 😉
Use dive
The manual method is so complex and unwieldy that the open source community created a tool specifically for
this task—it's called dive. Dive is a CLI tool that takes an image as input, parses its
file systems, and presents a text-based interactive UI in your terminal. It correlates the image layers for you,
letting you inspect the layer directories more easily.
When run against the Docker image from the Dockerfile above, it looks like this:
┃ ● Layers ┣━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │ Aggregated Layer Contents ├───────────────────────────────────────────────────────────────────────────────
Cmp Size Command └── var
69 MB FROM acee8cf20a197c9 └── lib
40 MB RUN /bin/sh -c apt-get update # buildkit └── apt
343 MB RUN /bin/sh -c apt-get install -y iputils-ping python3 python3-pip # buildkit └── lists
70 MB RUN /bin/sh -c pip3 install numpy # buildkit ├── auxfiles
0 B RUN /bin/sh -c rm -rf /var/lib/apt/lists/* # buildkit ├── lock
├── partial
│ Layer Details ├─────────────────────────────────────────────────────────────────────────────────────────── ├── ports.ubuntu.com_ubuntu-ports_dists_jammy-backports_InRelease
├── ports.ubuntu.com_ubuntu-ports_dists_jammy-backports_main_binary-arm64_Packages.lz4
Tags: (unavailable) ├── ports.ubuntu.com_ubuntu-ports_dists_jammy-backports_universe_binary-arm64_Packages.lz4
Id: 2bc27a99fd5750414948211814da00079804292360f8e2d7843589b9e7eb5eee ├── ports.ubuntu.com_ubuntu-ports_dists_jammy-security_InRelease
Digest: sha256:6e6fb36e04f3abf90c7c87d52629fe154db4ea9aceab539a794d29bbc0919100 ├── ports.ubuntu.com_ubuntu-ports_dists_jammy-security_main_binary-arm64_Packages.lz4
Command: ├── ports.ubuntu.com_ubuntu-ports_dists_jammy-security_multiverse_binary-arm64_Packages.lz4
RUN /bin/sh -c apt-get update # buildkit ├── ports.ubuntu.com_ubuntu-ports_dists_jammy-security_restricted_binary-arm64_Packages.lz4
├── ports.ubuntu.com_ubuntu-ports_dists_jammy-security_universe_binary-arm64_Packages.lz4
│ Image Details ├─────────────────────────────────────────────────────────────────────────────────────────── ├── ports.ubuntu.com_ubuntu-ports_dists_jammy-updates_InRelease
├── ports.ubuntu.com_ubuntu-ports_dists_jammy-updates_main_binary-arm64_Packages.lz4
Image name: where-the-roadmap-ends ├── ports.ubuntu.com_ubuntu-ports_dists_jammy-updates_multiverse_binary-arm64_Packages.lz4
Total Image size: 522 MB ├── ports.ubuntu.com_ubuntu-ports_dists_jammy-updates_restricted_binary-arm64_Packages.lz4
Potential wasted space: 62 MB ├── ports.ubuntu.com_ubuntu-ports_dists_jammy-updates_universe_binary-arm64_Packages.lz4
Image efficiency score: 90 % ├── ports.ubuntu.com_ubuntu-ports_dists_jammy_InRelease
├── ports.ubuntu.com_ubuntu-ports_dists_jammy_main_binary-arm64_Packages.lz4
Count Total Space Path ├── ports.ubuntu.com_ubuntu-ports_dists_jammy_multiverse_binary-arm64_Packages.lz4
2 28 MB /var/lib/apt/lists/ports.ubuntu.com_ubuntu-ports_dists_jammy_universe_binary-arm64_Pack ├── ports.ubuntu.com_ubuntu-ports_dists_jammy_restricted_binary-arm64_Packages.lz4
2 7.3 MB /usr/bin/perl └── ports.ubuntu.com_ubuntu-ports_dists_jammy_universe_binary-arm64_Packages.lz4
2 4.4 MB /usr/lib/aarch64-linux-gnu/libstdc++.so.6.0.30
2 2.9 MB /var/lib/apt/lists/ports.ubuntu.com_ubuntu-ports_dists_jammy_main_binary-arm64_Packages
2 2.0 MB /var/lib/apt/lists/ports.ubuntu.com_ubuntu-ports_dists_jammy-updates_main_binary-arm64_
2 1.7 MB /var/lib/apt/lists/ports.ubuntu.com_ubuntu-ports_dists_jammy-updates_universe_binary-ar
Dive is a wonderful tool, and I'm glad it exists—but sometimes, it falls short. Text-based interfaces are not the
easiest to use—sometimes Grafana is nicer than top.
Also, large images can overwhelm dive's capabilities. When inspecting large images, Dive consumes a lot of memory—sometimes the kernel will kill the Dive process before it outputs any data.
Docker Scout: a better way to inspect image internals
From a developer's perspective, it has always made sense to expect Docker image layer visualizations to exist in Docker Hub. After all, our Docker image data already lives in Docker Hub's backend.
I've often imagined inspecting Docker image internals in my browser, using a UI that looked something like this:

RUN pip3 install numpy

With Docker Scout, it appears that Docker is moving in that direction as a company. Today, if I navigate to the latest Postgres image in Docker Hub, I'm greeted with this:
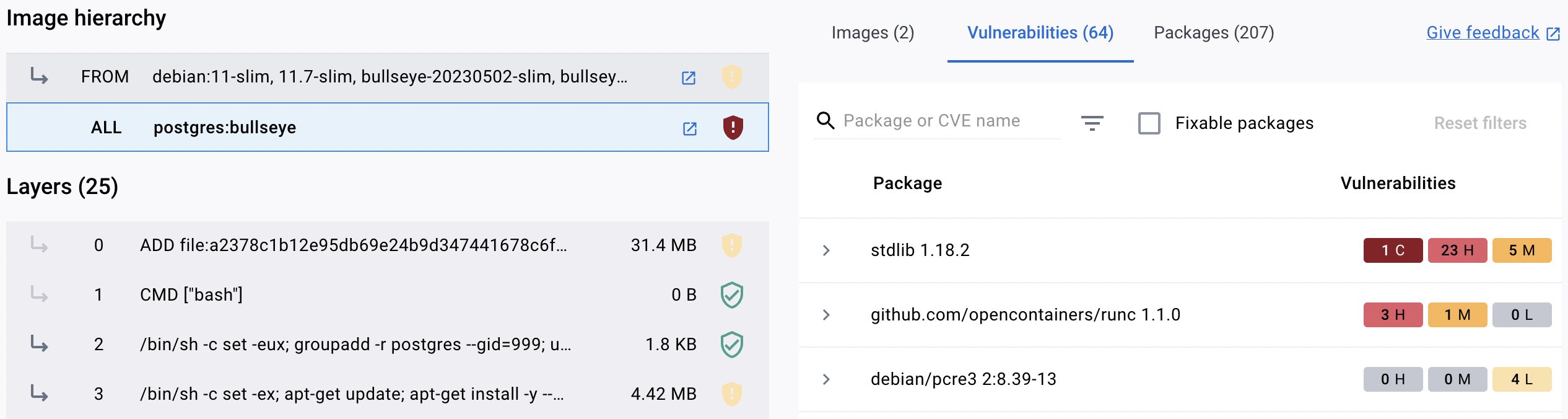
As a developer, this is exciting. This new UI lets me browse through image layer details visually, highlighting vulnerability and image size issues just like I want it to.
What took them so long?
When Docker Hub was first launched, it had two types of users:
- Developers, who download Docker images
- Software publishers, who upload Docker images
And Docker had to approach these two types of users differently.
After Docker debuted in 2013, developers immediately wanted to use their product. Docker containers standardize the packaging and deployment of everyone's software. Containers rapidly became popular in the software developer community.
Software publishers, however, were more hesitant. Why should they upload their software to a platform whose core utility is removing differentiation between software products?
Docker had to win them over in order to make Docker Hub successful. So instead of focusing on attracting developers, Docker Hub's design and feature set catered to software publishers.
For publishers, Docker Hub was a marketing site. It gave them a place to advertise their products. It did not let developers see Docker image internal details any more than car dealerships let you disassemble their engine blocks. Internal engineering details weren't put on display, they were hidden away, so shoppers stayed focused on the products themselves, not how they were made.
Docker Hub lacked developer-facing features for image size optimization and supply chain introspection because Docker already won over developers without those features. And in fact, those features have a tendency to make software publishers look bad—and they were the users Docker Hub still needed to win over to succeed.
This dynamic of serving both software publishers and developers made Docker Hub a two-sided platform.
Two-sided platforms
Two-sided platforms are businesses that have two different categories of users, and need both of them to participate in the platform in order for things to work. Usually, it's the motivation for using the platform that splits users into different groups.
While the two groups of users might not transact with one another directly, two-sided platforms are like markets—they don't create value unless vendors show up to sell and shoppers show up to buy.
In the tech industry, two-sided platforms are ubiquitous. When successful, these business models tend to produce network effects which propel businesses to sustained growth and profitability. After a certain point, the platform's size and established position in a space draws new users into the platform.
Once you know what you're looking for, two-sided platforms are easy to spot. Here are three examples.
On LinkedIn, there are two types of users—employees and hiring managers. Both groups participate for different reasons—employees want jobs, and hiring managers want to hire people.
Neither group could get what it wanted from the site until the other group started to participate. Once a sufficient number of each group signed up, it became the default place to be for new members of either group, and the site's growth perpetuated itself, all the way to getting bought by Microsoft for $26 billion.
YouTube
On YouTube, there are content creators and there are viewers. Viewers come to the site to see videos—content creators publish on the site in pursuit of good vibes, fame, and fortune.
After YouTube established a reputation as a place where content creators could succeed, more and more content creators showed up—and as they generated more content, more viewers came to visit. Once the platform grew beyond a certain size, content creators and viewers had no choice but to keep using it—each group needed the other, and they could only find each other through YouTube.
Docker Hub
In order for Docker Hub to be relevant, it needed software publishers to upload images and developers to download them. Once enough publishers were pushing images to Docker Hub, it would become the default place for developers to pull from. As the platform continued to grow, Docker Hub would cement its dominance as the one registry to rule them all.
What's past is prologue
At least, that was the plan. In reality, Docker (the company) declined, and Docker Hub never became "the one". When building a two-sided platform, startups have one product, but they have to find product-market fit twice. For Docker, this burden was too much to bear—in the end, it split Docker in half.
Now, after selling its enterprise business, Docker has reinvented itself, focusing its subscription service exclusively on developers and their employers. Docker Hub is no longer a two-sided platform, it's simple SaaS—customers pay a monthly fee in exchange for pushing and pulling their images.
This changes the calculus. There's no longer a "publisher" user persona for Docker to please—they're all in on developers. For Docker Hub, this paves the way for Docker Scout's image layer inspection functionality. For those of us watching from afar, it demonstrates the subtle, foundational coupling between a startup's business model and its product offering.