Scaling with Ansible is supposed to hurt
Red Hat's Ansible is one of the most popular ways for software teams to manage bare metal operating system installations and administer production configuration. It appeals to IT teams with its shallow learning curve, declarative syntax, and simplicity.
However, as companies start to scale, Ansible's design causes problems. For Red Hat, the ongoing costs to scale with Ansible are a feature, not a bug. Those costs are central to Red Hat's business model.
What is Ansible?
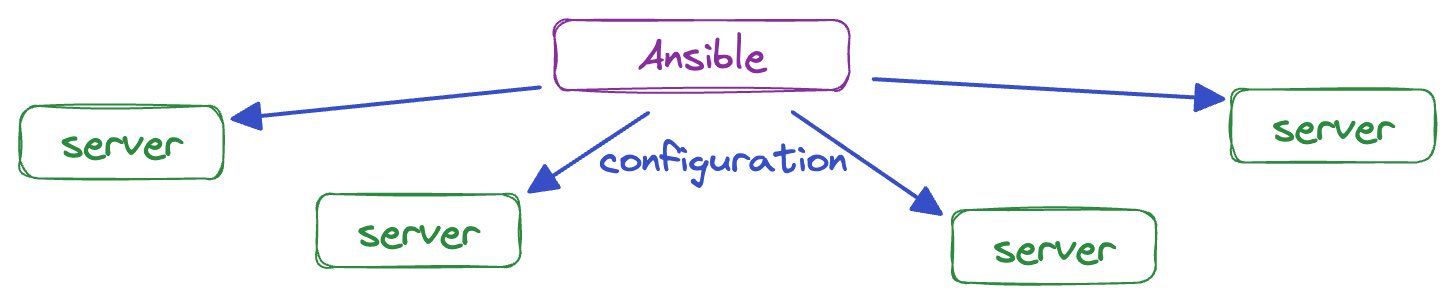
Ansible is an IT automation framework that is useful for running bits of configuration logic across a distributed system. Ansible has lots of functionality built in to help users automate tasks like:
- Creating and editing configuration files.
- Installing software packages.
- Managing system users.
These tasks are typically implemented as Python scripts, which Ansible copies to remote machines to run via SSH.
As an open source product, Ansible allows users to extend its functionality for themselves as necessary, and even provides mechanisms to share those extensions with the community. As a result, most common tasks now have free, pre-built modules for Ansible users.
Ansible's users specify their server configuration logic and inventory details in YAML files. At runtime, Ansible parses these YAML files and executes the configured logic against the targeted servers. Ansible encourages users to organize the logic into "roles" and "playbooks", which are run against the servers specified in their "inventory".
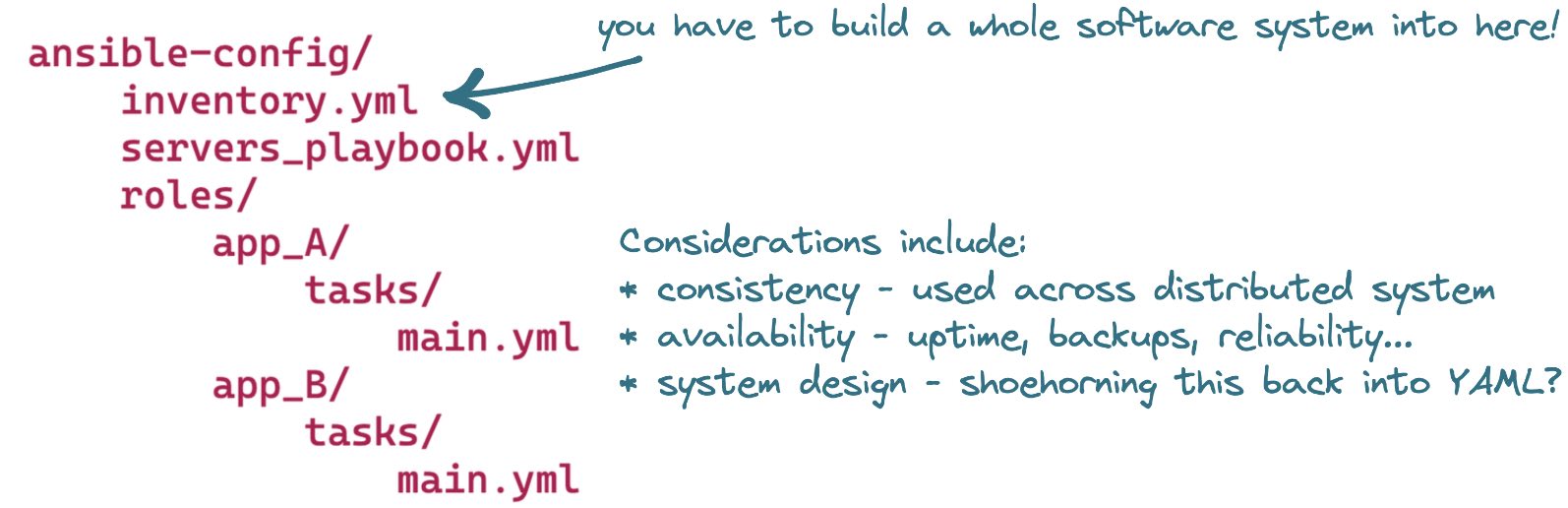
Users encode these details within a prescriptive, Ansible-specific directory structure that looks like this:
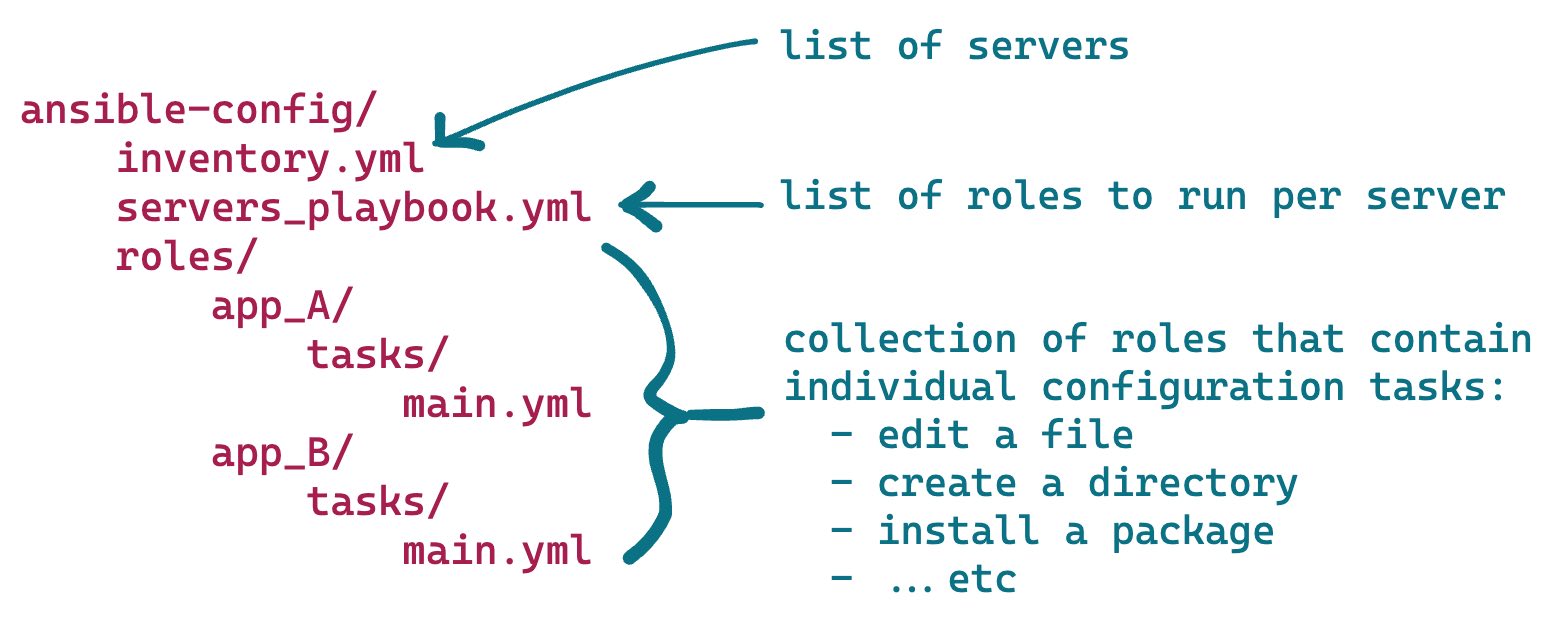
Typically, Ansible users check this directory structure into their version control system, editing and extending the logic it contains over time and treating their server configuration as code.
Why is it popular?
For sysadmin teams who maintain their servers by SSHing into them and running commands manually, Ansible provides a direct, one-to-one translation to an automated system. This is because running commands remotely over SSH is exactly how Ansible works. Users can simply translate each of their manual commands into Ansible-formatted YAML and enjoy the benefits of Ansible's IT automation.
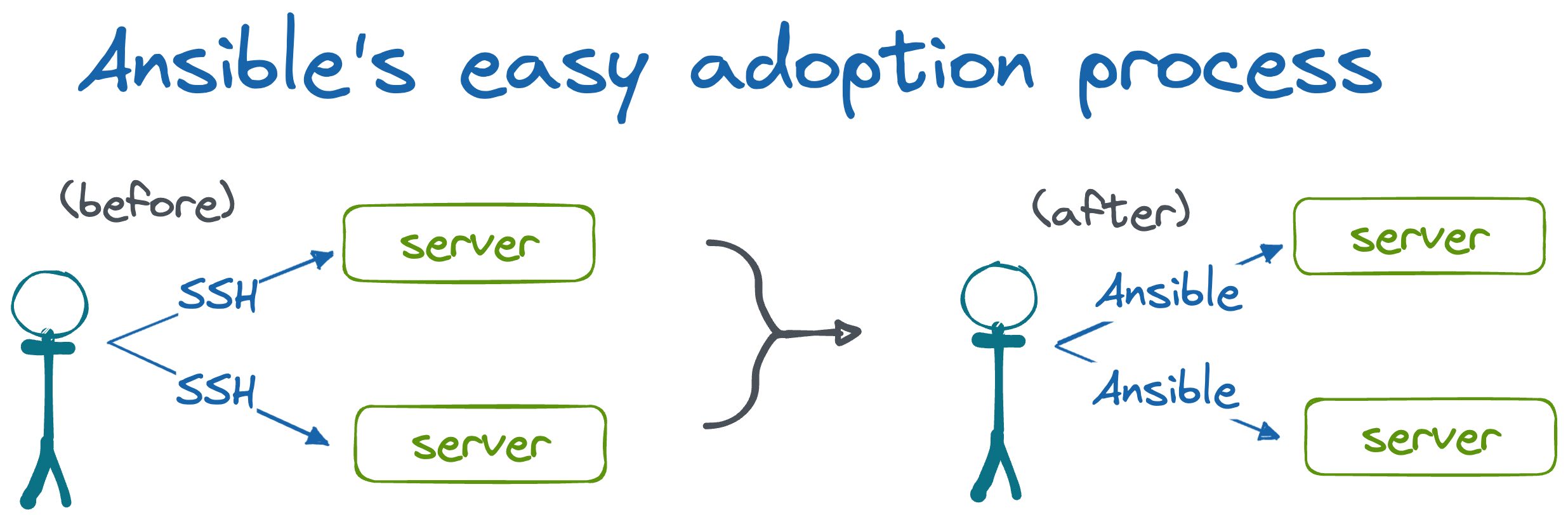
For startups, Ansible's low barrier to entry provides an easy on-ramp to automation that early-stage startup engineers can afford to adopt without investing too much time up front. Typically, their servers are already accessible via SSH, so there is no new software to install on their existing fleet to get started.
Most startups do not have the resources for a dedicated systems administration, DevOps, or SRE team. Ansible's simplicity makes it easy for generalist engineers to quickly pick up a bit of Ansible to automate away their immediate problems.
Ansible's free and open source licensing model makes it painless for both of these groups to adopt Ansible within their company without administrative overhead.
What happens as you scale?
Unfortunately, many startups find Ansible's benefits to be short-lived. As startups scale, Ansible's design causes growing pains, costing them engineering hours and forcing headcount increases. These growing pains result from two aspects of scaling a startup that balloon Ansible's complexity—more people and more code.
More people
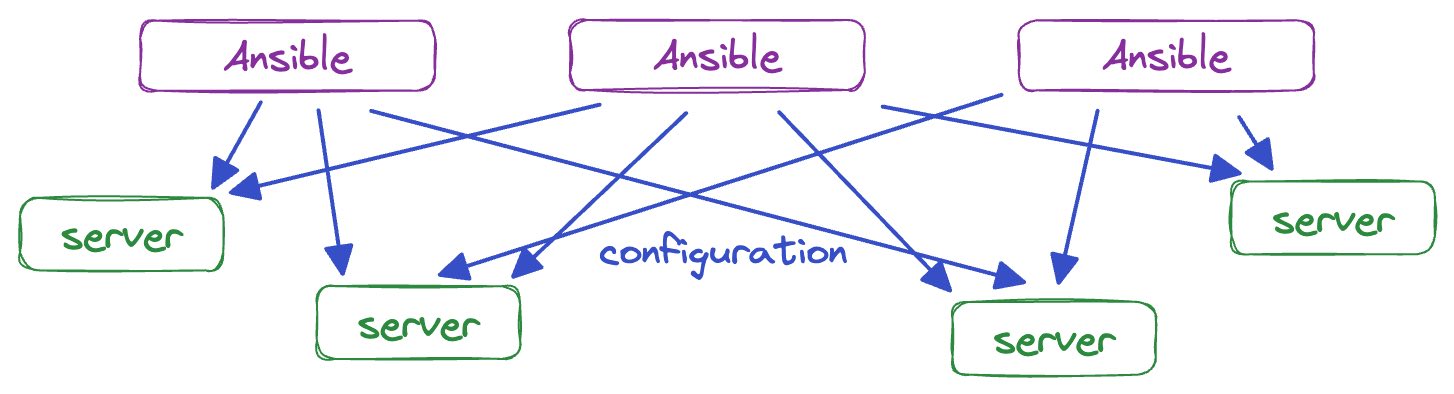
Ansible has no central repository for state—it doesn't track what changes it's made on a server, it just tries to enforce the desired state every time it configures a targeted machine. The source of truth for server state is the state of the server itself.
This design principle keeps things simple in the beginning, making Ansible an easy tool to get started with—but as headcount grows, it causes problems.
As startups scale, they hire new engineers, many of whom will start running Ansible against servers to configure them. As soon as multiple people start running Ansible against remote servers, the organization stops being able to track and control when any specific piece of configuration is applied to a server.
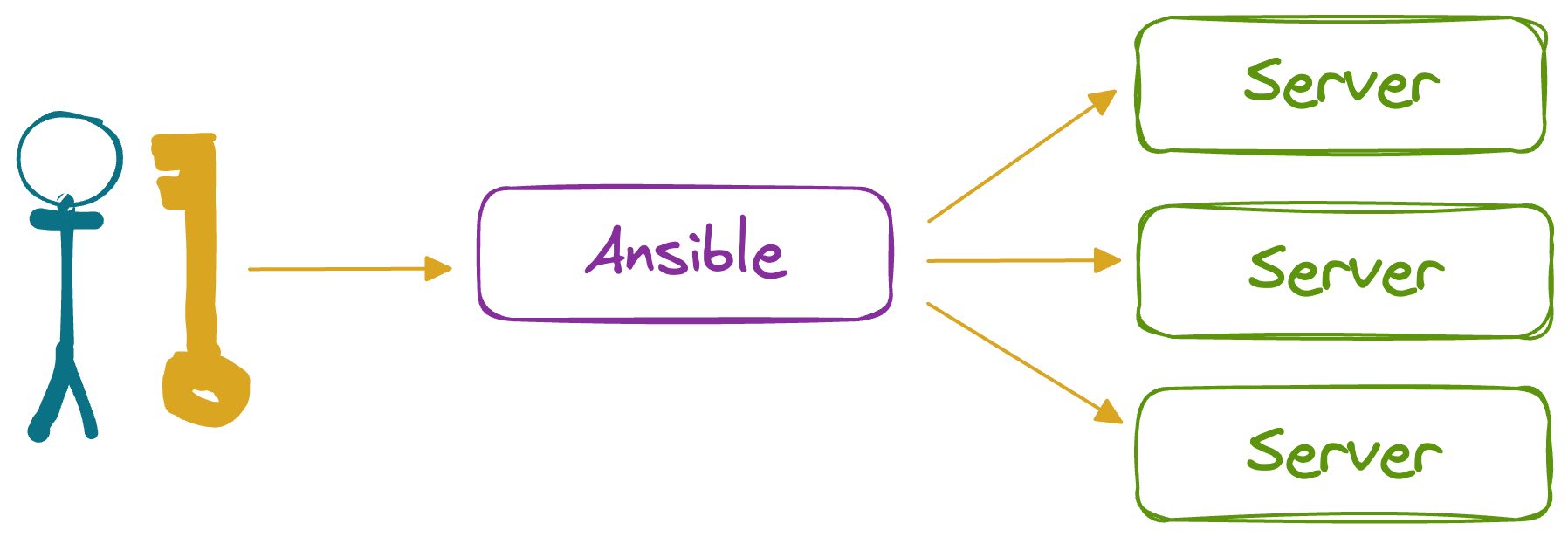
Ansible typically relies on SSH for transport and remote access, using whatever SSH key users give it when they run Ansible at the command line. Usually, this means the servers are left accessible for employees to log into via SSH, too.
Whether for debugging or production firefighting, engineers end up logging into the machines and changing configuration without using Ansible. This makes state tracking even more difficult, further hampering organizational scalability.
The natural solution to this problem is to centralize Ansible execution. Instead of having people run Ansible directly against remote machines, engineering teams have a centralized runner do it on their behalf. This centralized runner can track state, manage access control, and even provide a GUI.
There's a solution to all this—it's a paid offering that's part of the Red Hat Ansible Automation Platform (RHAAP).
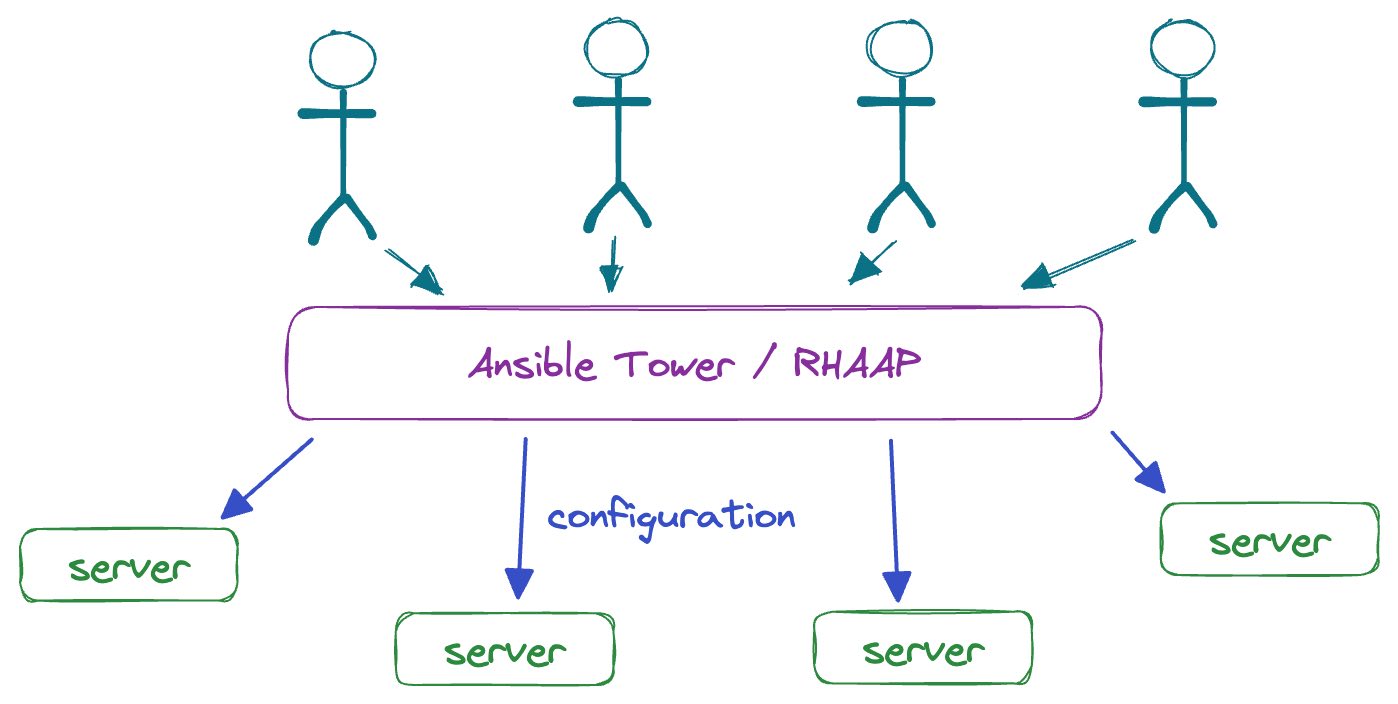
With RHAAP in view, we begin to see why Ansible exists without built-in solutions for state management or access control. These are problems that get worse as companies scale, and Red Hat wants to convert those companies into paying customers as they scale up.
With Ansible, Red Hat's business model is to offer solutions in its paid tier to problems that Ansible's architecture created in the first place.
More code
As a company's code base grows, its Ansible code base's complexity will increase. Unfortunately, Ansible is poorly suited to handle this complexity, and the tooling and infrastructure to do so becomes increasingly specialized and arcane.
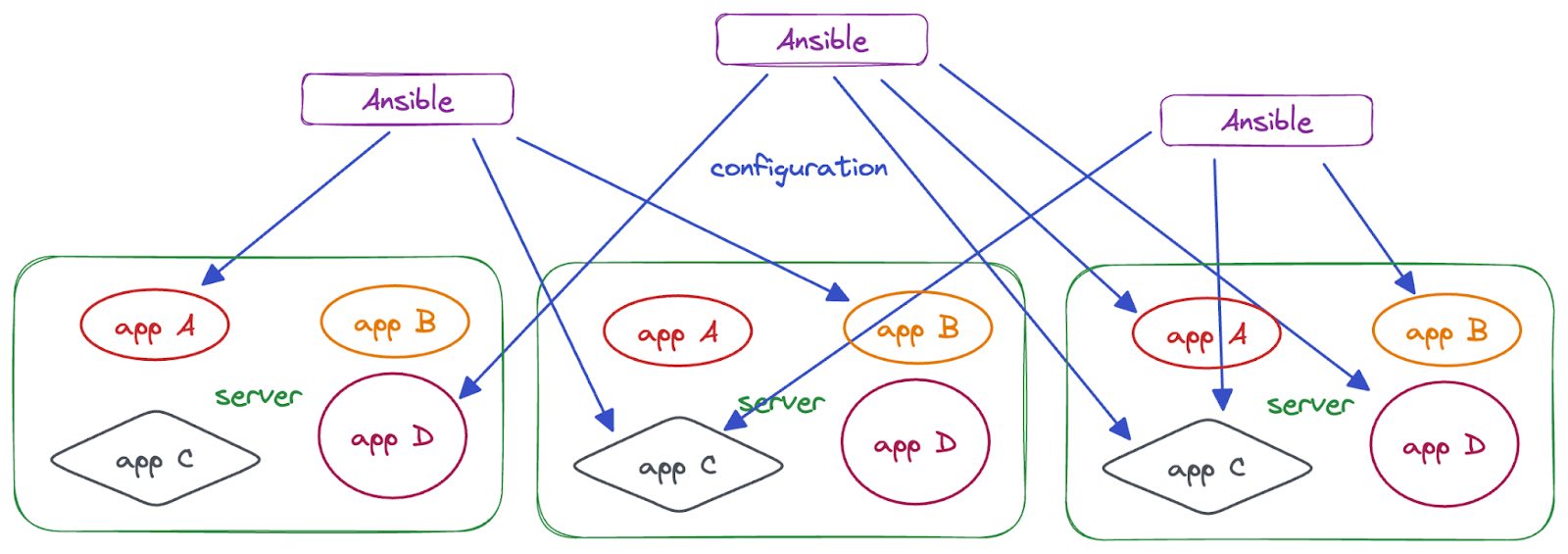
Domain-specific language complexity
YAML is not a language intended for encoding loops, conditionals, or complex string manipulation. It's not really a programming language at all. However, as applications grow in complexity, their configuration management and deployment mechanisms are probably going to need all of those constructs.
Ansible users can leverage these constructs by using Jinja2 templates, Ansible-specific YAML annotation structures, and snippets of Python encoded into YAML files. Developers can even write custom Ansible plugins to handle tricky, situation-specific problems.
# Does this look like YAML to you?
parsed_facts: |
{% set parsed_facts = {} %}
{% set network_info = ansible_facts.get('ansible_default_ipv4', {}) %}
{% set os_info = ansible_facts.get('ansible_distribution', '') %}
{% if network_info %}
{% set parsed_facts['ip_address'] = network_info.address %}
{% set parsed_facts['netmask'] = network_info.netmask %}
{% endif %}
{% if os_info %}
{% set parsed_facts['operating_system'] = os_info %}
{% endif %}
{{ parsed_facts | to_nice_yaml(indent=2) }}All of these changes turn Ansible's configuration file format into a more bespoke, domain-specific language over time. This increases maintenance cost, and erodes the ease-of-use that encouraged Ansible's adoption in the first place.
If it becomes complicated enough, an Ansible code base can even force teams to hire dedicated engineering specialists, sapping resources away from the company's actual business objectives. This becomes especially necessary when considering another endeavor that's required to scale a code base: testing.
Testing complexity
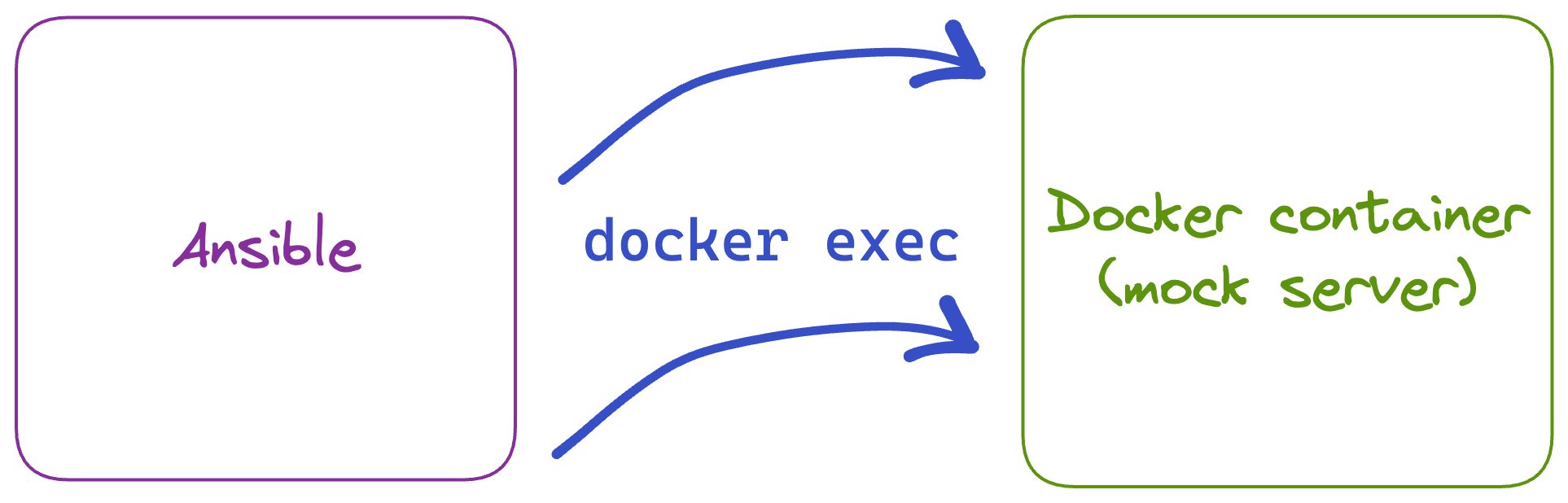
Ansible's SSH-based execution model makes it difficult to test before running in production. Developers often solve this using Molecule, a testing framework that runs Ansible roles against Docker containers and validates the resulting file system state within the container.
Experienced infrastructure engineers will see problems with this approach. Containers are not servers. Many server configuration tasks can't be tested this way. Additionally, running these kinds of automated tests often requires investing additional engineering time to build a more elaborate CI/CD system.
Server inventory complexity
Server inventory becomes increasingly dynamic as companies scale, and static files are a bad way to store dynamic data.
Ansible offers a way out of this problem, too—developers can implement dynamic inventory plugins which load their host data from remote sources instead of local YAML files. While effective, these extensions add to the list of Ansible-specific development efforts that companies need to invest in as they scale.
The 'free puppy' business model
All of these problems make Ansible "free like a puppy". The puppy is free, but the walks, attention, dog chow, grooming, and veterinary visits all cost both time and money.

Of course, Ansible has a comprehensive solution to all of these self-inflicted scalability challenges—sign a support contract with Red Hat. Companies are welcome to build on top of Ansible's free, open source core, but if it gets too complex to manage or expensive to hire for, they can just hire Red Hat's engineers instead.
Because of this, Ansible's scalability concerns are not design flaws for Red Hat—they're essential to its business model.

Keep this in mind when choosing to use Ansible in your startup. The core command-line driven tools are not given freely out of simple benevolence. They are an on-ramp to becoming a paying Red Hat customer later on, when your company scales up and has more money to spend.
Ansible is not free forever. As you grow, its design makes it a form of technical debt. You will be forced to pay down this technical debt when your company scales, either by paying Red Hat's engineers or your own.